Identifying and Handling Outliers in Data Analysis: A Comprehensive Guide
Related Articles: Identifying and Handling Outliers in Data Analysis: A Comprehensive Guide
Introduction
With great pleasure, we will explore the intriguing topic related to Identifying and Handling Outliers in Data Analysis: A Comprehensive Guide. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
Identifying and Handling Outliers in Data Analysis: A Comprehensive Guide
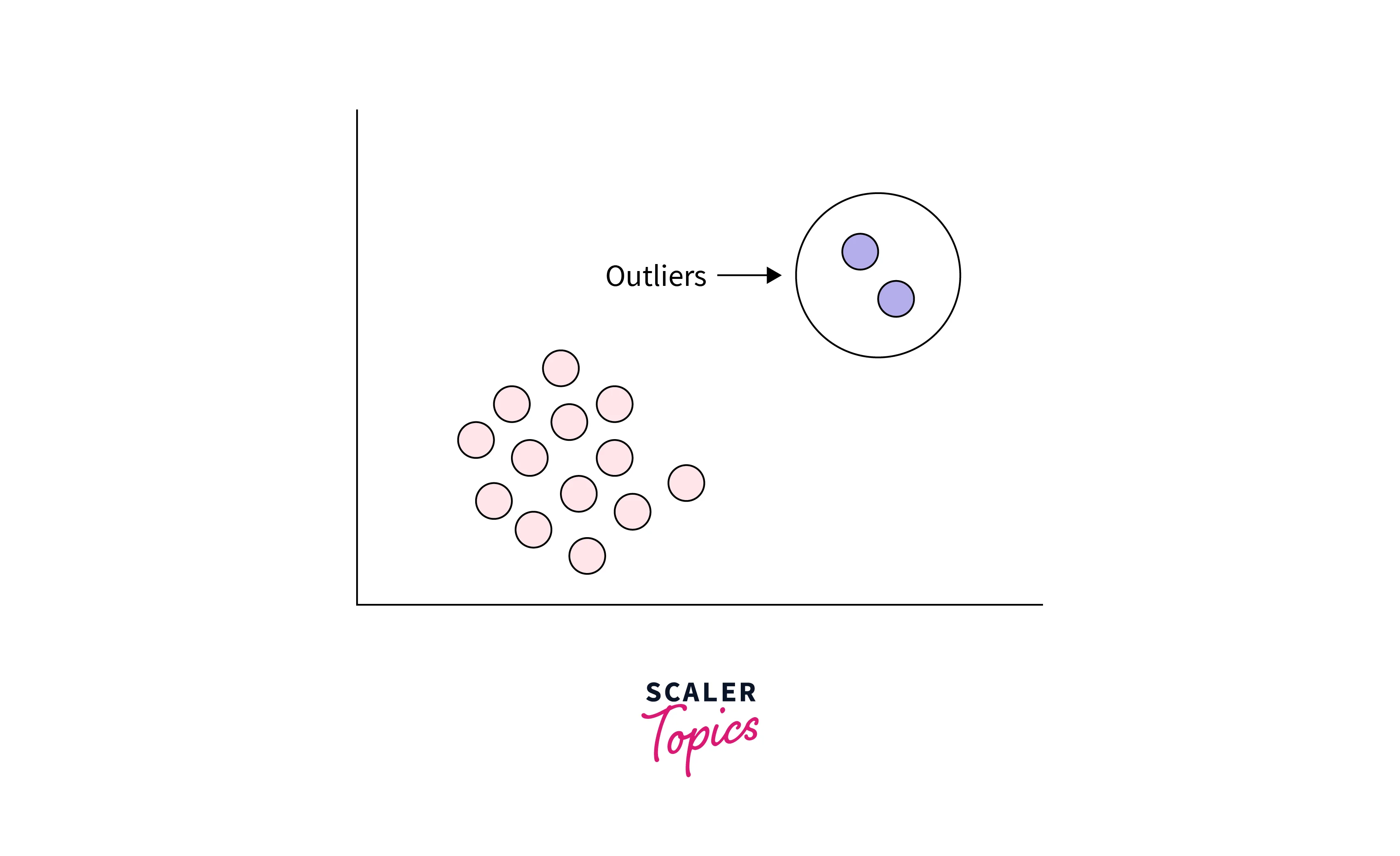
Outliers, data points that deviate significantly from the rest of the dataset, are often the subject of much scrutiny in data analysis. While they can be a source of frustration, understanding and addressing outliers is critical for obtaining accurate and reliable results. This guide provides a comprehensive overview of how to identify, analyze, and handle outliers in your data, emphasizing their importance and the benefits of addressing them effectively.
Understanding Outliers
Outliers are data points that lie outside the typical range of values observed in a dataset. They can arise due to various reasons, including:
- Data entry errors: Mistakes in data entry can lead to erroneous values that are far from the expected range.
- Measurement errors: Faulty instruments or incorrect measurement techniques can produce inaccurate readings.
- Sampling bias: Non-random sampling methods can lead to data that does not represent the underlying population accurately.
- Natural variation: Some datasets naturally exhibit extreme values, especially in fields like finance or healthcare, where data can be highly volatile.
Importance of Identifying Outliers
Identifying outliers is crucial for several reasons:
- Accurate statistical analysis: Outliers can significantly skew statistical measures like mean, standard deviation, and correlation, leading to misleading conclusions.
- Improved model performance: Outliers can negatively impact the performance of machine learning models by introducing noise and skewing the learning process.
- Data quality assessment: Outliers can indicate data entry errors, measurement issues, or other problems that need to be addressed to ensure data quality.
- Understanding data patterns: Outliers can sometimes highlight unusual or interesting patterns in the data that would otherwise go unnoticed.
Methods for Identifying Outliers
Several methods can be employed to identify outliers in a dataset. The choice of method depends on the nature of the data, the size of the dataset, and the desired level of precision.
1. Visual Inspection:
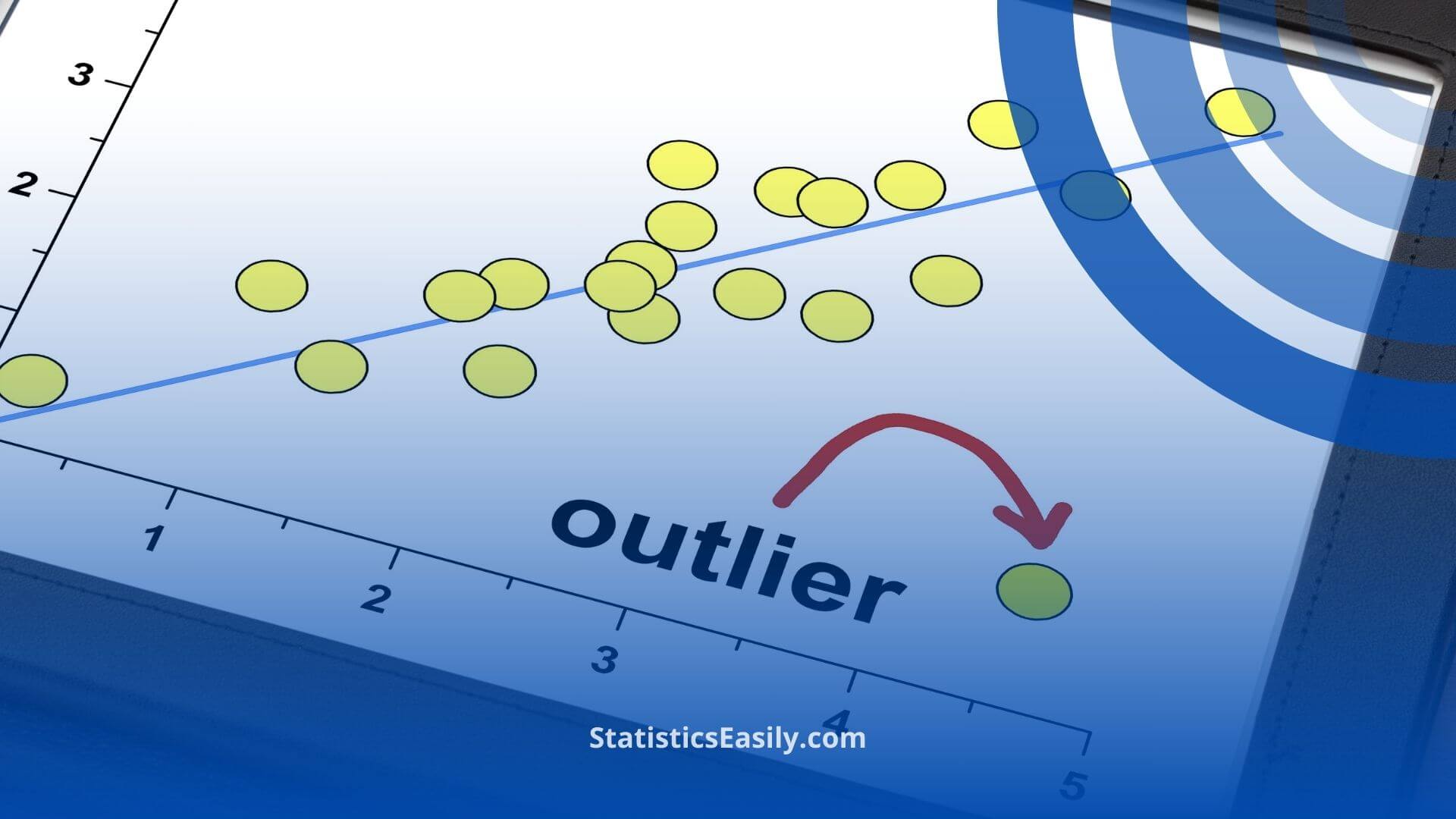
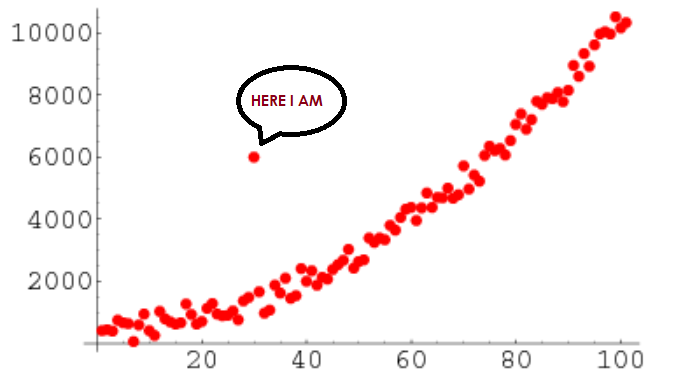
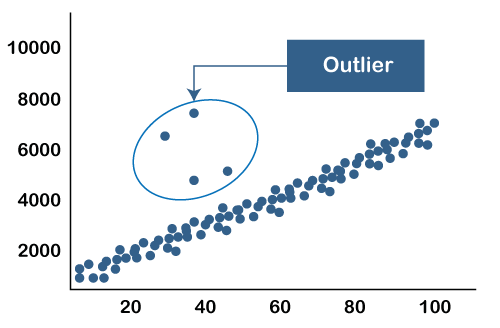
- Scatter plots: Plotting data points on a scatter plot can reveal outliers visually as points that are far away from the general trend.
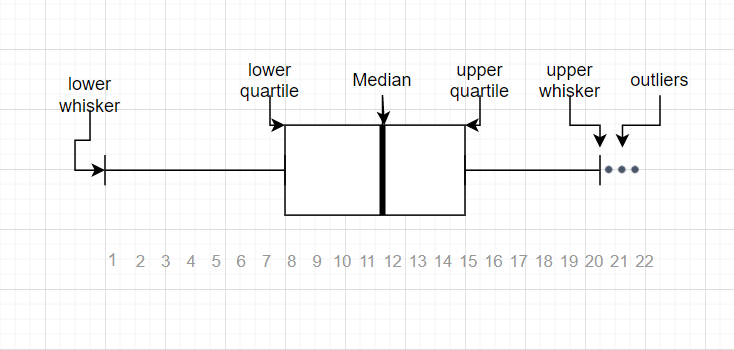
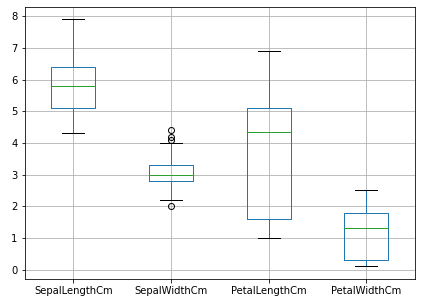
- Box plots: Box plots display the distribution of data using quartiles and whiskers, with outliers depicted as individual points beyond the whiskers.
- Histograms: Histograms visualize the frequency distribution of data, allowing for the identification of outliers as points that lie outside the main distribution.
2. Statistical Methods:
- Z-score: This method calculates the number of standard deviations a data point is away from the mean. Values with a Z-score greater than 3 or less than -3 are often considered outliers.
- IQR (Interquartile Range): The IQR represents the range between the first and third quartiles. Data points lying beyond 1.5 times the IQR from the upper or lower quartile are considered outliers.
- Tukey’s fences: This method utilizes the IQR and the upper and lower quartiles to define fences that identify outliers.
- Mahalanobis distance: This method calculates the distance of a data point from the center of the data distribution, considering the correlation between variables.
3. Machine Learning Techniques:
- Isolation Forest: This algorithm isolates outliers by randomly partitioning the data space, identifying points that are easily isolated.
- One-Class Support Vector Machines (OCSVM): This technique learns a boundary around the normal data points, classifying points outside the boundary as outliers.
Handling Outliers
Once outliers are identified, it is important to determine the appropriate course of action. The decision to handle outliers depends on the context and the reason for their presence.
1. Removing Outliers:
- Deletion: Removing outliers can be a straightforward approach, especially when they are clearly due to data entry errors or measurement issues. However, this method should be used cautiously, as it can lead to information loss if outliers represent genuine data points.
- Trimming: Trimming involves removing a fixed percentage of data points from both ends of the distribution, potentially eliminating outliers. This approach is less sensitive to individual outliers compared to deletion.
2. Replacing Outliers:
- Imputation: Replacing outliers with more plausible values based on the remaining data can be useful when outliers are likely due to errors. Common imputation techniques include mean imputation, median imputation, and k-nearest neighbor imputation.
- Winsorization: This method replaces extreme values with the nearest non-outlier value within a defined range, preserving the overall distribution while mitigating the impact of outliers.
3. Transformation:
- Logarithmic transformation: Transforming data using logarithms can compress the range of values, reducing the impact of outliers.
- Box-Cox transformation: This method finds the optimal power transformation to normalize the data and reduce skewness, potentially mitigating the influence of outliers.
4. Modeling Outliers:
- Robust statistical methods: Using robust statistical methods that are less sensitive to outliers, such as the median instead of the mean, can provide more accurate results in the presence of outliers.
- Machine learning models: Some machine learning models, like random forests and support vector machines, are inherently robust to outliers.
Choosing the Right Approach
The best approach for handling outliers depends on the specific context and the reasons for their presence. Consider the following factors:
- Nature of the outliers: Are they clearly due to errors or do they represent genuine data points?
- Impact on analysis: How much do outliers affect the statistical measures and model performance?
- Data size and distribution: Is the dataset large enough to justify removing outliers? How skewed is the distribution?
- Domain knowledge: Do you have any insights into the data that can help interpret outliers?
FAQs
1. What if I have a lot of outliers?
If a significant portion of the data consists of outliers, it may indicate a problem with the data collection process or the underlying distribution. In such cases, it is important to investigate the root cause of the outliers and address them accordingly.
2. Should I always remove outliers?
Removing outliers is not always the best solution. It is essential to consider the reasons for their presence and their impact on the analysis. In some cases, outliers may contain valuable information that should not be discarded.
3. How do I know if I’ve handled outliers correctly?
After handling outliers, re-evaluate the data and check if the statistical measures and model performance have improved. Look for any unusual patterns or trends that may indicate remaining outliers.
4. Can I use outliers to my advantage?
Yes, outliers can sometimes provide valuable insights into data patterns or anomalies. For example, in fraud detection, outliers can signal suspicious transactions that require further investigation.
Tips for Handling Outliers
- Document your decisions: Clearly document the methods used to identify and handle outliers, along with the rationale behind each decision.
- Use multiple methods: Employ multiple methods for identifying outliers to ensure a comprehensive approach.
- Be cautious with removal: Only remove outliers if they are clearly due to errors or if their presence significantly skews the data.
- Consider the context: The appropriate approach for handling outliers depends on the specific context and the goals of the analysis.
Conclusion
Outliers are an integral part of data analysis and can provide valuable insights if handled appropriately. By understanding the reasons for their presence, employing various identification methods, and choosing the most suitable approach for handling them, data analysts can ensure the accuracy and reliability of their results. Remember that outliers are not always a problem, and sometimes they can be used to uncover hidden patterns and improve the understanding of the data.


Closure
Thus, we hope this article has provided valuable insights into Identifying and Handling Outliers in Data Analysis: A Comprehensive Guide. We hope you find this article informative and beneficial. See you in our next article!